20.03.2025 Christoph Epping
Echtzeitdaten gehören zu den besonderen Unternehmensschätzen, die sich dank moderner Cloud-Technologien endlich umfassend erschließen und in geschäftliche Analysen einbinden lassen. Aber was sind die besten Services in diesem Umfeld?
In unserer von Microsoft Azure bestimmten Projektwelt schwanken wir immer wieder zwischen Stream Analytics und Databricks Streaming. Bei unserem Industrie-Kunden igus hat Databricks das Rennen gemacht – nicht unbedingt, weil der Service hinsichtlich der Performance oder Kosten allgemeine Vorteile bietet. Er fügt sich einfach homogener in die bereits bestehende Databricks-Landschaft ein. Das heißt: Der Aufwand für die Datenanbindung und -aufbereitung ist deutlich geringer.
Aber wie sind wir bei der Implementierung vorgegangen? Welche Learnings und Best Practices haben wir mitgenommen? Werfen wir einen genaueren Blick auf das Projekt und den konkreten Anwendungsfall.
Databricks Lakehouse ruft nach Databricks Streaming
igus bildet das typische Industrie-4.0-Szenario ab: Produktions- und Statusdaten von Maschinen sollen laufend mit weiteren Geschäftsdaten verknüpft und „Near-Realtime“ in Berichten und Dashboards visualisiert werden. Perspektivische sollen bis zu 800 Anlagen an die Lösung angebunden werden.
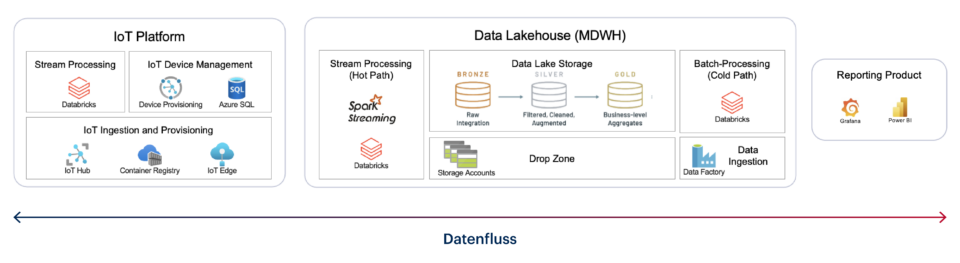
Für den ersten Aufbau hatten wir Stream Analytics genutzt und damit alle Anforderungen erfüllt. Im weiteren Projektverlauf sollte sich aber der Einsatz von Databricks Streaming als sinnvoller erweisen. Der Hauptgrund: Das vorhandene Databricks Lakehouse stellt viele der benötigten Stammdaten bereits in aufbereiteter Form zur Verfügung. Infolgedessen müssen auch weniger Quellen angebunden werden. Der Wechsel zum Databricks-Dienst führt also schon kurzfristig zu spürbaren Einsparungen in Sachen Zeit und Geld.
Hinzu kommt, dass beim Umzug weder die Datenquellen noch die bestehenden Berichte und Dashboards angepasst werden müssen. Für sämtliche Aufgaben stehen entsprechende Schnittstellen und Software-Lösungen zur Verfügung. Es gilt lediglich, eine individuelle Logik zu erstellen. Also alles ganz einfach? Grundsätzlich schon. Allerdings sind die Anforderungen an moderne Echtzeitstrecken durchaus anspruchsvoll. Infolgedessen gibt es einige Dinge zu beachten, auf die ich im Folgenden eingehen möchten.
Hohe Anforderungen, die es zu erfüllen gilt
Die Vorgaben für die Echtzeitstrecke von igus sind im Bereich Industrie 4.0 „State-of-the-Art“:
- Streaming-Daten sollen auf ihrem Weg durch geschäftliche Informationen angereichert werden
- Komplexe Datenströme sind nach unterschiedlichen Kriterien zu splitten und zu parallelisieren
- Zur Produktionswertermittlung muss auf vergangene Daten desselben Streams zugegriffen werden
- Durchlaufzeiten vom Senden bis zum Dashboard dürfen maximal drei Sekunden betragen
- Nach einem Abbruch muss gewährleistet sein, dass alte und neue Daten umgehend wieder hergestellt werden
- Die Daten sollen über Power BI in einem Streaming Dataset bereitgestellt werden
Mit unserer Lösung können wir alle diese Anforderungen erfüllen. Die Implementierung von Databricks Streaming erfolgte mit applyInPandasWithState. Um den fortlaufenden Stream der Produktionswerte einzelnen Schichten zuordnen zu können, ermitteln wir die akkumulierte Summe der Delta-Werte des aktuellen Schichtrhythmus. Die Darstellung wird schichtbezogen live im Dashboard auf Tagesbasis aktualisiert. Zum Speichern des Delta-Wertes sowie des zuletzt bekannten Wertes bietet sich eine In-Memory-Datenbank an. So bleibt der Storage Account unbeansprucht, während sich die Durchlaufzeit verringert.
applyInPandasWithState bietet eine entsprechende Funktion – hier der Code:
stream = stream.groupBy('MachineId').applyInPandasWithState(
# individually developed feature for state processing
statefunc,
# schema of the data output
"AssembledDelta INTEGER, MachineId STRING, State INTEGER, ShiftDate STRING, InventoryNo STRING",
# schema of the in-memory state chart
"timestamp TIMESTAMP, Assembled INTEGER, State INTEGER",
"append",
GroupStateTimeout.NoTimeout
)
def statefunc(key, pdf_iter, state):
pdf = pd.concat(list(pdf_iter), axis=0)
state_str = ""
# If state exists, combine in-memory state and new arriving stream data
if state.exists:
(old_ts, old_assembled, old_state, ) = state.get
state_str = f"old_ts={old_ts}, old_assembled={old_assembled}, old_state={old_state}"
pdf = pd.concat([pd.DataFrame({'timestamp': [old_ts], 'Assembled': [old_assembled], 'State': [old_state]}), pdf])
# Sort by timestamp to properly forward fill null values and to calculate the delta
pdf = pdf.sort_values(by=["timestamp"])
# ----------- Fill empty rows
pdf["Assembled"] = pdf["Assembled"].replace(to_replace=-1, method="ffill")
pdf["State"] = pdf["State"].replace(to_replace=-1, method="ffill")
# -----------
# Calculate delta value
pdf['AssembledDelta'] = pdf.Assembled.diff()
# Drop the first row from the timestamp sorted state to only keep the latest one
if state.exists: pdf = pdf.iloc[1:]
# Update the in-memory state
state.update((pdf.iloc[-1].timestamp, pdf.iloc[-1].Assembled, pdf.iloc[-1].State,))
# ----------- Shift Date Handling
# Additional logic for output dataframe
# Calculate shift date by extracting the date from the timestamp substracted by 6 hours
pdf['timestamp'] = pdf.timestamp - timedelta(hours=6)
pdf['timestamp'] = pdf['timestamp'].dt.strftime("%Y-%m-%dT%H:%M:%S.%fZ")
pdf = pdf.rename(columns={"timestamp": "ShiftDate"})
pdf.drop(columns=["Assembled"], inplace=True)
# -----------
yield pdf
Databricks Streaming – ein kurzes Resümee
Das Databricks Lakehouse und die darum platzierten Services sind ein sehr stimmiges Gesamtpaket. Deshalb ist meine erste Empfehlung: Wer schon auf Databricks setzt, der braucht erst gar nicht mit Alternativen herumzuspielen. Vor diesem Hintergrund bietet Databricks Streaming eine hohe Flexibilität rund um die Nutzung von Datenströmen. Speziell applyInPandasWithState ist ein mächtiges Werkzeug, mit dem die Streams über die Funktionen hinweg verarbeitet werden können. Hinzu kommt die Möglichkeit, auf Vergangenheitsdaten zugreifen zu können, ohne zusätzliche Daten zu persistieren.
→ Lesen Sie auch: Databricks Lakehouse – Der Gamechanger für Ihr Geschäft
Berücksichtigt werden müssen die Performance sowie die damit verbundene Durchlaufzeit und das Memory Management im betreffenden Cluster, wobei sich die Cluster für alle Bedürfnisse skalieren lassen. Letztendlich ist eine Verschneidung von allen verfügbaren Daten möglich – also eine runde Sache für Unternehmen, die ihre Echtzeitdaten konsequent und abteilungsübergreifend nutzen wollen.
Zum Autor

Christoph Epping
Senior Consultant – IoT
Christoph Epping gehört zu den Top-IoT-Experten bei ORAYLIS. Gemeinsam mit unseren Kunden realisiert er Echtzeit-Lösungen von der Ideenfindung bis zur konkreten Umsetzung.



Kommentare (0)