Predictive Analytics ist bei der Polizei ein viel beachtetes Thema. Polizeibehörden in Deutschland wie auch anderen Ländern versuchen zunehmend Verbrechen mit Hilfe von intelligenten Algorithmen und Methoden zu prognostizieren. Besonders häufig werden Predictive Policing im Kontext von Wohnungseinbrüche eingesetzt, wie Beispiele aus Berlin, NRW und München zeigen. Der Grund: Hier wird ein systematisches Vorgehen vieler Täter angenommen – sprich: Straßen, Blöcke oder Stadtteile werden planmäßig ausgekundschaftet und heimgesucht. Damit einher geht die Hoffnung, das geheime Muster der Einbrecher zu identifizieren. Wie aber funktioniert Predictive Policing? Im Folgenden werde ich mich auf Verbrecherjagd in Chicago begeben. Dabei nutze ich eine Lösung, die auf Power BI basiert, Microsofts führendem Analyse-Dienst.
Wie komme ich an die Daten?
Die Datenbasis meiner Lösung bilden also die Wohnungseinbrüche in Chicago/Illinois. Wie ich an solche – aus deutscher Perspektive – vertraulichen Daten komme? Auf jeden Fall ganz legal. Das Zauberwort lautet „Open Data“: Öffentliche Institutionen, private Unternehmen und NGOs öffnen zunehmend ihre Datentöpfe, damit die Welt davon profitieren kann. Dieser Trend ist auch in Deutschland auf dem Vormarsch. Beispielsweise stellt Köln unter Offene Daten Köln Daten von seltsam bis spannend ins Netz. Meine Favoriten sind die Auslastung der städtischen Parkhäuser und die Position aller Ampeln.
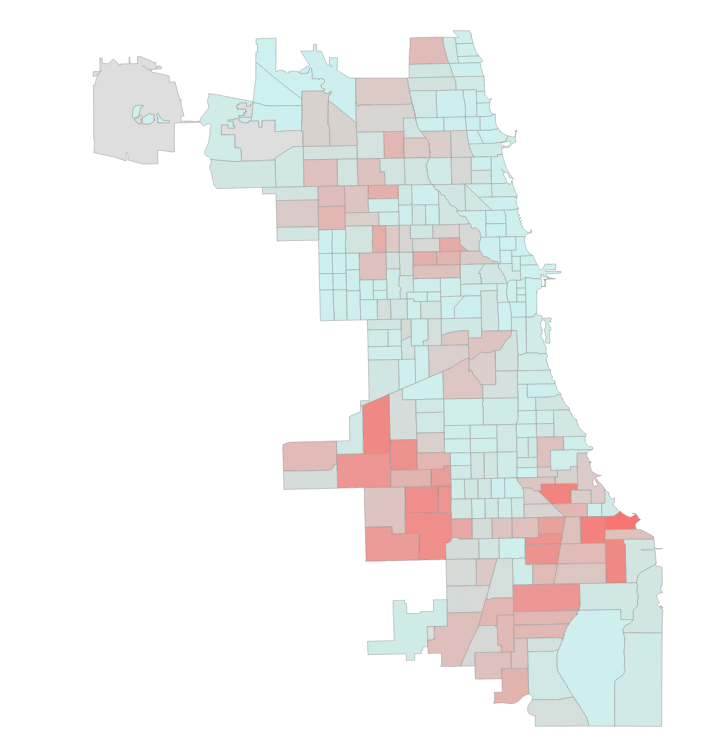
Wie so oft sind uns die Amerikaner aber ein paar Schritte voraus. So finden sich im „Chicago Data Portal“ Daten von Wohnungseinbrüchen über Drogendelikten bis hin zu Mord – genügend Futter also, um mich an einer kleinen Predictive Analytics Lösung zu versuchen, mit der ich vorhersagen kann, ob und wann in Chicago innerhalb der nächsten 72 Stunden eingebrochen wird. Als Werkzeuge dienen mir Power BI und die Programmiersprache „R“.
Wie groß sollte das Vorhersage-Gebiet sein?
Die Stadt Chicago stellt ihre Einbruchsdaten relativ detailliert bereit, vor allem in Bezug auf Straße bzw. Block und Tatzeitpunkt. Was komplett fehlt, sind Informationen zur Beute. Aber das wäre vielleicht auch zu viel des Guten. Nach einer ersten Sichtung habe ich mir überlegt, für welche Gebiete ich Predictive Analytics anwenden möchte. Die Datensätze umfassen jeweils Adresse, Block, Polizeibezirk („Beat“), Community, Ward und District. Adresse und Block waren mir zu fein granular, da Chicago mit rund 2,7 Millionen Einwohnern alles andere als eine kleine Stadt ist. Indes erschienen mir Community (77), Ward (50), District (22) als zu umfangreich. Schließlich sind manche Districts größer als viele Städte in Deutschland. Somit lohnt sich eine Prognose auf dieser Ebene kaum. Daraufhin stellten für mich die insgesamt 272 Beats einen guten Kompromiss dar.
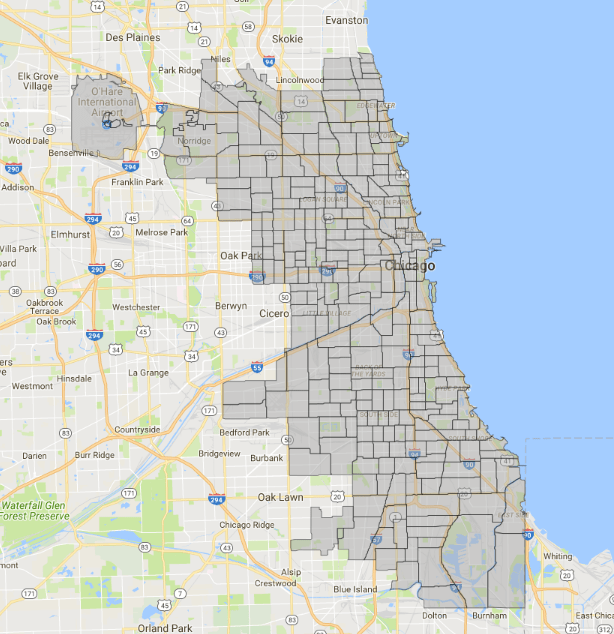
Bei einem Ausbau der Lösung wäre es auch möglich, eigene Gebiete zu definieren oder die Stadt systematisch – wie auf einem Schachbrett – zu zerteilen. Ein Vorteil dieser vordefinierten Bereiche ist, dass es hierzu schon entsprechende Shape Files gibt. Aber dazu komme ich später.
Welches Verfahren ist das richtige?
Zunächst eine besonders wichtige Frage: Wie soll die Prognose überhaupt erzeugt werden? Cortana, Siri und Alexa konnten mir darauf keine Antwort geben. Dafür bekam ich den Hinweis, dass es in Chicago heute regnet und ich meinen Schirm nicht vergessen soll. Die Künstliche Intelligenz ist auf dem Vormarsch.
Letztlich lässt sich das Ganze als Klassifizierungsproblem interpretieren: Ich möchte für jeden Tag und für jeden Polizeibezirk vorhersagen, ob dort eingebrochen wird oder nicht. Wie oft und bei welcher Hausnummer die Einbrecher zuschlagen, wird nicht betrachtet. Infolgedessen gibt es zwei Klassen: „Einbruch“ und „Kein Einbruch“. Als Klassifikationsverfahren habe ich Random Forest genutzt – also nichts Exotisches. Ich wollte erst einmal schauen, ob überhaupt etwas bei der Analyse rauskommt.
Im nächsten Schritt habe ich die Daten in eine Form gebracht, mit der der Algorithmus etwas anfangen kann. Zudem galt es, jeden Polizeibezirk mit Informationen anzureichern. Als erstes habe ich für jeden Polizeibezirk die historischen Einbrüche pro Tag errechnet, zum Beispiel in den letzten 3, 6, 12, 24 und 48 Tage. Ebenso habe ich soziodemografische Daten hinzugezogen, wie die Anzahl der Bewohner in einem Polizeibezirk sowie deren Alter und Ethnien. Auch hierbei handelt es sich um Open Data, konkret Zensus-Daten von 2012.
Wie trainiere ich ein Modell für Predictive Policing?
Anhand der Daten der vergangenen 365 Tage konnte ich nunmehr für jeden Monat ein Predictive Policing Modell mit R und Random Forest trainieren. Diese Modelle habe ich dazu verwendet, um Einbruchsprognosen rückwirkend zu simulieren. Ich habe also beispielsweise mit den Daten von April 2016 bis Ende April 2017 ein Modell für die Prognose der Einbrüche im Mai 2017 trainiert. Auf die gleiche Weise habe ich für insgesamt 6 Monate rückwirkend Prognosen erzeugt. Infolgedessen stand mir für jeden Tag und jeden Polizeibezirk eine Prognose zur Verfügung, die ich mit den tatsächlichen Einbrüchen in dieser Zeit vergleichen konnte.
Noch ein paar Erfahrungswerte zu den verwendeten Werkzeugen: Meist gibt es ein dediziertes Back-End, bei dem Power BI lediglich als Front-End aufgesetzt wird. Power BI konnte seine Stärken beim Laden, Integrieren und Bereinigen der Einbruchs- und Zensus-Daten ausspielen. R war indes äußert praktisch, um neben der Prognoseerstellung auch aufwändige Datentransformationen zu gestalten, wie zum Beispiel die Berechnung der historischen Einbrüche. Das Resultat ist dann ein recht komplexer Query-Dependencies-Baum, in dem Abfrage auf Abfrage aufbaut.
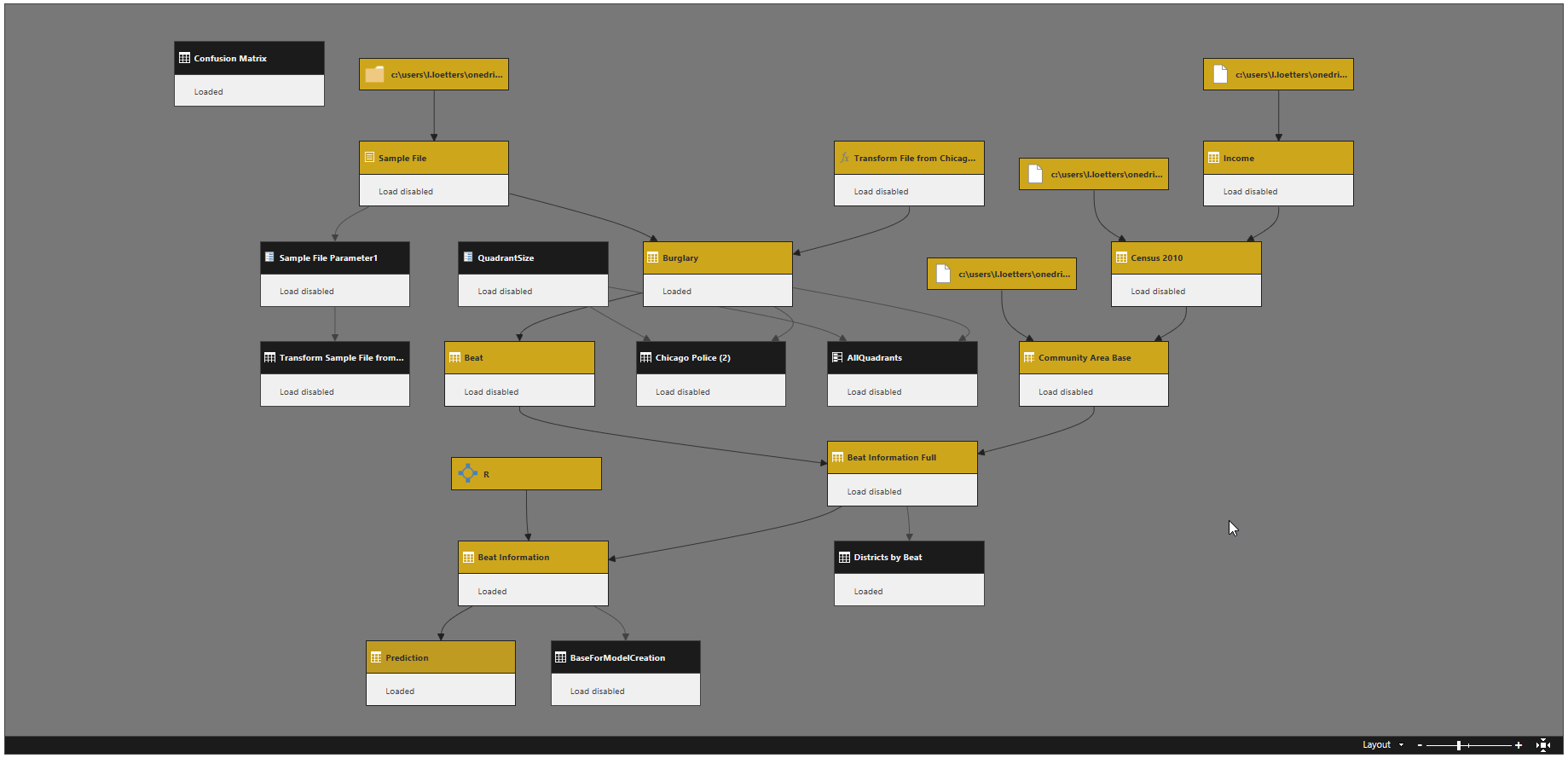
Wie sehen die Ergebnisse aus?
Wie sich zeigt, geschehen bei der Entwicklung des Predictive Policing Modells wie so oft 80 Prozent der Arbeiten „unter der Haube“ – sprich: Daten werden beschafft, integriert und transformiert, wir trainieren das Modell und erstellen entsprechende Prognosen. Für das große Aha-Erlebnis sorgt aber erst die Visualisierung. Ich habe in diesem Zusammenhang einen Podcast erstellt, der zeigt, wie Power BI für die Darstellung der Prognoseergebnisse verwendet werden kann:
Dazu habe ich den Bericht als solchen mit der Power-BI-Funktion „Publish to Web“ bereitgestellt, sodass Sie sich parallel durchklicken können:
Wie ich finde, zeigen die Inhalte klar und deutlich, dass eine Vorhersage von Verbrechen möglich ist. Selbstverständlich ist das hier gezeigte Modell noch ausbaufähig. Grundsätzlich ist aber gut zu erkennen, welche Möglichkeiten sich aus der Kombination von offenen Daten und modernen Analysetools wie Power BI eröffnen.
Möchten auch Sie Power BI nutzen, um mehr Werte aus Ihren Daten zu ziehen? Dann informieren Sie sich weiter unter Power BI oder laden Sie sich unser Whitepaper Power BI als moderne Analyseplattform herunter.






Kommentare (0)