Continuous Deployment hat in den vergangenen Jahren die Entwicklung von Anwendungen und Datenbanken massiv beschleunigt. Änderungen werden laufend nach festen Kriterien produktiv gesetzt, wobei Tests, Qualitätssicherung und Roll-out automatisiert erfolgen. Neben der hohen Geschwindigkeit zeichnet sich die Methodik auch durch große Nutzerfreundlichkeit aus. Für Unternehmen auf dem Weg zur Data Driven Company bedeutet dies deutliche wirtschaftliche Vorteile.
Allerdings können sich auch Fehler bei der „kontinuierlichen Bereitstellung“ neuer Versionen einschleichen. So berichten Entwickler immer wieder von Datenverlusten auf der Produktivebene. Auch wir sind in unseren Projekten schon auf dieses Problem gestoßen und haben im Zuge dessen eine Lösung entwickelt, die ich im Folgenden beschreiben möchte. Ich beziehe mich dabei auf ein SQL-Server-Database(Dacpac)-Projekt.
Aufbau der Entwicklungsumgebung
Zum Einstieg ein paar Worte über unsere Entwicklungsumgebung: Als Basis nutzen wir Azure DevOps. Die verschiedenen Cloud-Dienste unterstützen nicht nur die Sprint-Planung im Rahmen unseres agilen Vorgehens. Ebenso können Git-Repositories sowie Build- und Release-Pipelines für Continuous Integration und Continuous Deployment genutzt werden. Je nach Größe des Projektes setzen wir auf verschiedene Umgebungen, wobei alle Bereiche von der Entwicklung über die Integration bis hin zur Produktivsetzung mittels Continuous Deployment bespielt werden. Die Datenbank wird dann innerhalb eines Dacpac-Projektes gehalten. Und eben in diesem Aufbau ist es immer wieder zu den bereits angesprochenen Datenverlusten gekommen.
Automatisches Löschen verhindern
Wie können Sie nun verhindern, dass Daten beim Continuous Deployment ungewollt verloren gehen? Zunächst gilt es, die automatische Löschfunktion auszusetzen. Hierfür wählen Sie in den Publish Profiles des Projektes die Einstellung „Block incremental deployment if data loss might orrur“. Somit wird die Bereitstellung gestoppt, wenn Datenverluste drohen. Aktionen, die außerhalb des eigentlichen Deployments durchgeführt werden sollen, lassen sich mit Pre- oder Post-Deployment-Skripten realisieren. Die notwendigen Transformationen könnten demnach innerhalb eines Pre-Deployments-Skripts eingebunden werden.
Allerdings: Dacpac erstellt im ersten Schritt des Deployments alle notwendigen Skripte und führt erst danach das Pre-Deployment aus (siehe Abb.). Daher bricht der gesamte Prozess ab, wenn Sie entsprechende Transformationen oder Löschoperationen auf der Datenbank durchführen – selbst, wenn diese zuvor im Pre-Deployment bewusst umgesetzt wurden. Das heißt: Die Automatisierung ist komplett ausgesetzt. Deshalb haben wir einen unabhängigen, vorgelagerten Schritt eingefügt, durch den wir eine beliebige Anzahl an SQL-Skripten ausführen können.
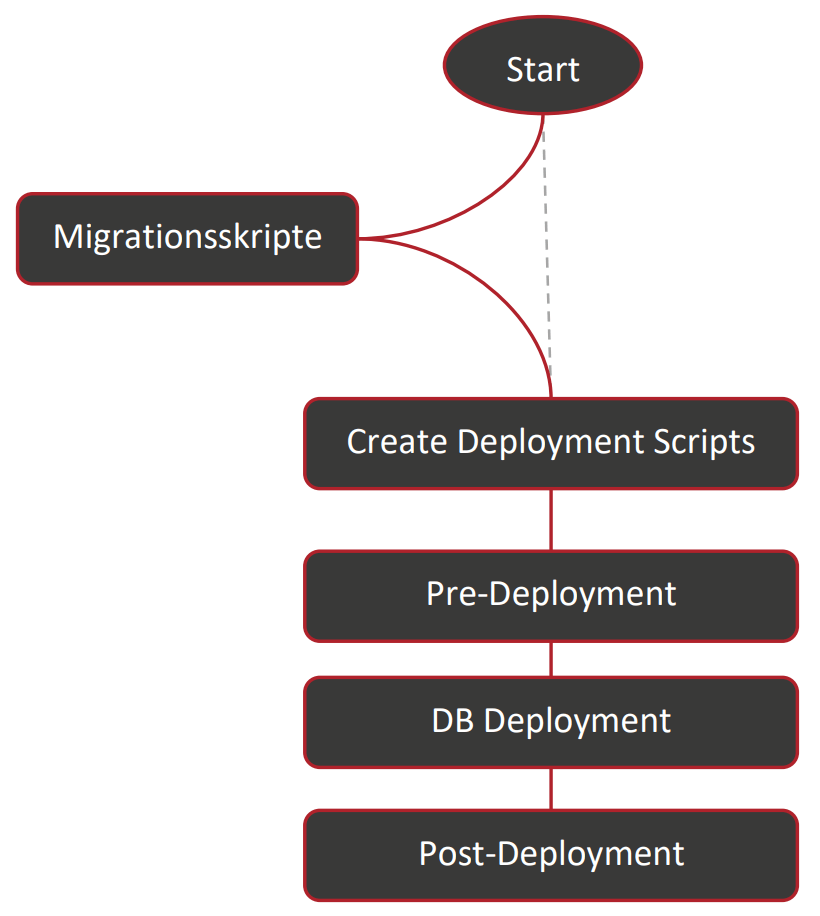
Release-Pipeline und Migrationsskript aufbauen
Grundvoraussetzung für den Einsatz des Skriptes – und damit einer fehlerfreien Automatisierung des Deployment-Prozesses – ist, dass die Migrationsskripte selbst innerhalb der Quellcodeverwaltung platziert sind und in der entsprechenden Build-Pipeline im Artefakt veröffentlicht werden. Das Artefakt wird wiederum von der Release-Pipeline genutzt.
Und so bauen Sie die Release-Pipeline und das Migrationsskript auf: Sie legen über Visual Studio beispielsweise im Dacpac-Projekt einen Ordner an, der die künftigen SQL-Skripte beinhaltet. Die Reihenfolge lässt sich über die Dateibezeichnung festlegen. Wir nutzen in unserer von Features getriebenen Entwicklung die fortlaufenden Task-Nummern und setzen diese an den Anfang des Dateinamens. Sollte es innerhalb eines Tasks erforderlich sein, verschiedene Skripte auszuführen, können Sie diese zusätzlich nummerieren. Zudem benötigen Sie das PowerShell-Skript, das die Migrationsskripte ausführt. Jenes liegt ebenfalls im Projektordner:
-
param
-
(
-
[parameter(Mandatory = $true)] [String] $resourceGroup,
-
[parameter(Mandatory = $true)] [String] $sqlServerName,
-
[parameter(Mandatory = $true)] [String] $SqlServerAdminLoginId,
-
[parameter(Mandatory = $true)] [String] $sqlServerAdPassword ,
-
[parameter(Mandatory = $true)] [String] $databaseName,
-
[parameter(Mandatory = $true)] [String] $queryFolder
-
)
-
Write-Host „Setting Server and Database“
-
$sqlServer = Get-AzSqlServer -ResourceGroupName $resourceGroup | where {$_.ServerName -eq $sqlServerName}
-
$sqlDatabase = Get-AzSqlDatabase -ResourceGroupName $resourceGroup -Servername $sqlServerName| where {$_.DatabaseName -eq $DatabaseName}
-
Write-Host „Getting files“
-
$queryNames = Get-ChildItem -Path $queryFolder | Sort-Object
-
Write-Host „Executing SQL-Tasks“
-
ForEach ($queryName in $queryNames){
-
# es sollen nur .sql Dateien ausgeführt werden
-
If ( $queryName.Name.Substring($queryName.Name.Length – 4) -eq ‚.sql‘){
-
Write-Host „Executing $($queryName.Name)“
-
$query = Get-Content „$($queryFolder)\$($queryName)“| Out-String
-
$query_exe = @{
-
‚Database’= $sqlDatabase.DatabaseName
-
‚ServerInstance‘ = $sqlServer.FullyQualifiedDomainName
-
‚Username‘ = $SqlServerAdminLoginId
-
‚Password‘ = $sqlServerAdPassword
-
‚Query‘ = $query
-
}
-
Invoke-Sqlcmd @query_exe -verbose
-
Write-Host „Execution of $($queryName.Name) finished“
-
}
-
}
-
Write-Host „Finished executing SQL-Tasks“
Um nun die Skripte für das Release bereitzustellen, müssen Sie die Build-Pipeline anpassen. Sie erstellen zwei weitere Artefakte – eines für die SQL-Skripte sowie eines für das PowerShell-Skript:
-
– task: PublishPipelineArtifact@1
-
displayName: ‚Publish Artifact – Migrationsskripte‘
-
inputs:
-
targetPath: ‚$(System.DefaultWorkingDirectory)\<PFADZUMORDNER>\Migration‘
-
artifact: ‚Migrationsskripte‘
-
publishLocation: ‚pipeline‘
-
– task: PublishPipelineArtifact@1
-
displayName: ‚Publish Artifact – Migration.Main‘
-
inputs:
-
targetPath: ‚$(System.DefaultWorkingDirectory)\ <PFADZUMORDNER>\Migration.Main.ps1‘
-
artifact: ‚Migration.Main‘
-
publishLocation: ‚pipeline‘
Nachdem die Build-Pipeline erfolgreich durchgelaufen ist, werden die Release-Pipelines erweitert. Hierfür nutzen Sie die von Azure DevOps bereitgestellte Benutzeroberfläche. Die neu erstellten Artefakte werden dem Agent Job hinzugefügt, indem Sie unter „Artifact download“ zusätzlich „Migrationsskripte“ sowie Migration.Main selektieren:

Release-Pipeline erweitern
Im Anschluss erweitern Sie die Release-Pipeline. Hierzu fügen Sie als erstes einen „Azure-PowerShell“-Task hinzu, der zu Beginn unseres Datenbank-Deployments ausgeführt wird:

Die notwendigen Berechtigungen erhält der Task über einen zuvor angelegten Azure Ressource Manager, der die Managementebene innerhalb eines Azure-Kontos darstellt. Als Script Type wählen Sie „Script File Path“ aus. Wenn die Build-Pipeline zuvor erfolgreich abgeschlossen wurde, können Sie „Browse Script Path“ auswählen und zum PowerShell-Skript navigieren. Alternativ kann der Pfad auch manuell eingegeben werden. In den Script Arguments müssen jetzt noch die folgenden – fett hinterlegten – Parameter übergeben werden:
-
-resourceGroup ‚<RESSOURCEGROUP>‘ -sqlServerName ‚<SQLSERVERNAME>‘ -SqlServerAdminLoginId ‚<LOGINID>‘ -sqlServerAdPassword ‚<PASSWORD>‘ -DatabaseName ‚<DATABASE>‘ -queryFolder ‚$(System.DefaultWorkingDirectory)/<PFADZUMORDNER>/Migrationsskripte‘
Dadurch werden Datenbank-Server, Datenbank-Name, die zugehörige Authentifizierung sowie das Verzeichnis für die SQL-Skripte festgelegt. Die Parameterwerte können bei Bedarf auch als Variablen aus einem KeyVault eingebunden werden. Abschließend nutzen wir die „Latest installed version“ der Azure PowerShell. Alle weiteren Einstellungen des Tasks bleiben auf Standard. Es bedarf also nur ein paar kleiner Anpassungen und schon können Sie innerhalb Ihrer Release-Pipeline ein fehlerfreies Continuous Deployment ohne ungewollte Datenverluste gewährleisten.
Wollen Sie mehr zur Entwicklung und dem laufenden Betrieb moderner Datenlösungen erfahren? Dann schauen Sie mal auf der Seite Big Data Engineering vorbei oder informieren Sie sich zu unserem Training Data Lakehouse: Cloud-Plattformen aufbauen und geschäftlich nutzen.




Kommentare (0)