Machine-Learning(ML)-Modelle bilden bekanntlich die Basis für ganz unterschiedliche Lösungen der Künstlichen Intelligenz (KI). Im Rahmen von Machbarkeitsstudien können Unternehmen solche Modelle gezielt entwickeln. Damit allein ist es allerdings nicht getan. Ein konkreter Nutzen entsteht erst, wenn das Modell produktiv gesetzt wird. Und genau dieser Schritt stellt bislang für viele Unternehmen eine scheinbar unüberwindbare Hürde dar, da die Implementierung in die Unternehmensprozesse viel aufwendiger als gedacht ist und nach speziellen Kenntnissen zu KI in der Cloud verlangt.
Daher wird in diesem Beitrag ein Ansatz in der Microsoft Azure Cloud mit dem Azure Databricks Service gezeigt. Hier finden Sie relativ einfache Möglichkeiten zur Produktivsetzung von ML-Modellen. Im Folgenden möchte ich darauf genauer eingehen.
Kurz vorweg: Was ist Azure Databricks?
Bei Databricks handelt es sich zunächst um eine auf Apache Spark basierende Datenverarbeitungsplattform, die auch über Microsoft Azure als Service bereitgestellt wird. Dieser Service ist grundsätzlich auf ein einfaches Handling durch den Nutzer ausgelegt. In nur wenigen Schritten richten Sie neue Arbeitsbereiche ein und legen diese für die interaktive Zusammenarbeit zwischen Big Data Engineering und Data Scientists aus. Ebenso können Sie Datenstreaming bzw. die Verarbeitung und Analyse von Echtzeitdaten ermöglichen. Dazu lässt sich Azure Databricks problemlos mit anderen Services aus der Microsoft Cloud kombinieren. Mehr zu den Funktionen des Dienstes finden Sie im Beitrag Wir beantworten die 5 wichtigste Fragen zu Databricks. Wir konzentrieren uns nun auf die Möglichkeiten, die Databricks bei der Produktivsetzung von ML-Modellen bietet.
Produktivsetzung mit Databricks
Grundsätzlich soll ein produktives ML-Modell für KI in der Cloud zwei Anforderungen voll automatisiert erfüllen: Einerseits gilt es, die eigentliche Kernaufgabe zu bewältigen, wobei es sich im Regelfall um eine Form der Prognose handelt. Andererseits muss sich das Modell in gewissen zeitlichen Abständen neu trainieren, um kontinuierliche Verbesserungen oder eine Anpassung an neue Gegebenheiten zu ermöglichen. Sie betrachten diese Aufgaben also getrennt voneinander. Entsprechend erstellen wir zunächst ein Produktivskript sowie ein Trainingsskript (Abb. 1).
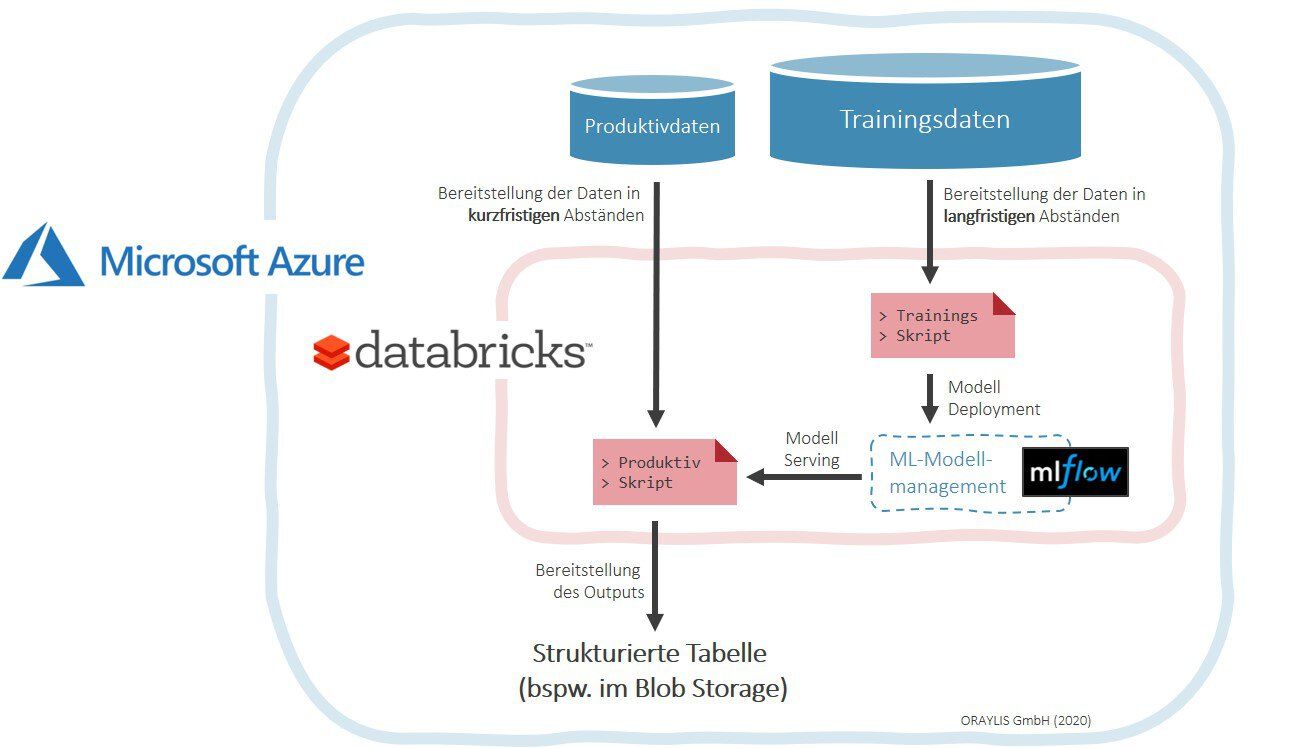
Das Produktivskript führt also die eigentliche Prognose durch. Zu diesem Zweck müssen Sie die erforderlichen Daten so präparieren und bereitgestellen, dass die Situation am gewünschten Zeitpunkt in der Zukunft ausreichend gut beschrieben wird. Natürlich liegen viele der relevanten Informationen noch nicht vor – wie beispielsweise das Wetter der kommenden Woche. Daher werden fehlende Informationen als Annahmen ergänzt oder auf andere Weise erzeugt. Die resultierenden Datensätze lassen sich nunmehr durch unser vorhandenes ML-Modell führen, wobei die Ergebnisse in einer strukturierten Tabelle festgehalten und einem beliebigen Azure Storage für den Endanwender abgelegt werden.
Die Aufgabe des Retrainings für unser bereitgestelltes ML-Modell erfolgt hingegen über das sogenannte Trainingsskript. Die Datenbasis hierfür ist zwar deutlich größer. Allerdings beruht auch das Retraining auf Vergangenheitsdaten, sodass der Algorithmus nur aus realen und korrekt gelabelten Fällen seine Regeln erlernen kann. Anschließend wird das neu trainierte ML-Modell mit seiner Vorgängerversion verglichen und im Falle einer Verbesserung ausgetauscht. In der reinen Azure-Databricks-Umgebung erscheint diese Aufgaben immer noch relativ kompliziert. Aus diesem Grund steht mit MLflow ein spezielles Framework als Unterstützung zur Verfügung.
Verwaltung über MLflow
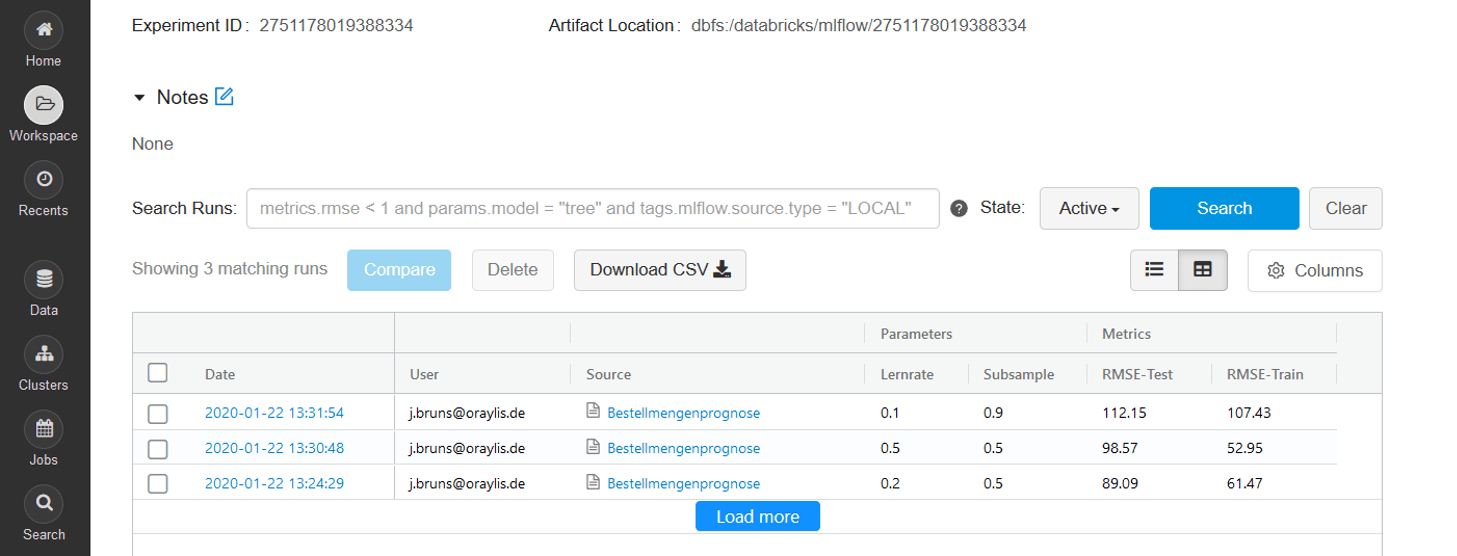
Bei MLflow handelt es sich um eine Plattform, mit der sich ML-Modelle über ihren gesamten Lebenszyklus hinweg übersichtlich verwalten lassen. Die Verwendung ist relativ simpel: Im Rahmen von sogenannten Experimenten können diverse Trainingsdurchläufe mit unterschiedlichen Parametereinstellungen aufgezeichnet und nachverfolgt werden. So lassen sich beispielsweise zuvor definierte Parameter und Metriken einfach loggen und auch nach dem Training zu Informationszwecken wieder abrufen. Zudem werden die Modellauswahl, -bereitstellung und -versionierung für den produktiven Einsatz unterstützt. Grundsätzlich kann der Entwickler Python, R oder Java verwenden.
In der Abb. 2 wird anhand eines Beispiels das Logging eines MLflow Experiments gezeigt, welches hier drei Runs mit unterschiedlichen Parameterausprägungen umfasst. Demnach wurden also drei ML-Modelle mit ebenfalls unterschiedlichen Evaluationsergebnissen trainiert, auf die im Detail auch einzeln aus dem Produktivskript zugegriffen werden kann.
Fazit
Grundsätzlich verschafft dieser Beitrag nur einen groben Einblick in die vielfältigen Möglichkeiten von Azure Databricks im Kontext von ML-Modellen für KI-Lösungen. Die Mehrwerte werden aber dennoch schnell ersichtlich. Sie ergeben sich vor allem aus dem Einsatz der MLflow-Komponente. So hilft die Funktionalität des Loggings bereits bei einer Entwicklung erster Prototypen, die Auswirkungen von unterschiedlichen Hyperparametereinstellungen im Blick zu behalten. Im Zuge der vollumfänglichen Produktivsetzung lassen sich dann sowohl das Retraining des Modells als auch seine Bereitstellung ganz einfach automatisieren. Ebenso ist ein nachvollziehbares Monitoring implementierbar. Zusammenfassend kann also das gesamte ML-Modellmanagement gut abgedeckt werden, was dem übergeordneten Ziel einer erfolgreichen Lösungsimplementierung in die bestehenden Unternehmensprozesse sehr entgegenkommt.
Wollen Sie mehr zur erfolgreichen Umsetzung von KI-Projekten in Ihrem Unternehmen erfahren? Dann informieren Sie sich weiter auf der Seite Künstliche Intelligenz oder besuchen Sie unseren Workshop Von der Vision zum ersten KI-Fahrplan.




Kommentare (0)