Systeme, die auf Künstliche Intelligenz (KI) basieren, werden bei unseren Kunden inzwischen in vielen Gebieten eingesetzt. Sie leisten dort einen konkreten Mehrwert für das tägliche Geschäft. Dabei meine ich nicht nur gängige Anwendungsfälle, wie Predictive Maintenance in der Produktion oder Churn-Szenarien und Absatzprognosen in der Administration. Einige unserer Kunden verfügen inzwischen auch über einzigartige Produkte, die kundenspezifische und ganz individuelle Problemstellungen lösen. Ein Beispiel sind Einbruchsprognosen, die Verbrechensschwerpunkte vorhersagen und dadurch einen effektiven Einsatz von Polizeikräften ermöglichen.
Wie jedoch die Praxis zeigt, besteht auf dem Weg von der ersten Idee bis zur fertigen Lösung stets die Gefahr, dass selbst ambitionierte und bekannte KI-Cases mit guten Erfolgsaussichten scheitern. Der Grund hierfür sind einige Fehler, die im Folgenden näher beschrieben werden. Ebenso werden Maßnahmen zur Fehlervermeidung aufgezeigt.
1. Fehler: Übertriebene Erwartungen an die Machbarkeit
Häufig werden Ideen zu Anwendung einer KI von den Fachbereichen oder sogar direkt von der Geschäftsführung mit großem Elan auf den Tisch gebracht. Umso größer ist die Enttäuschung, wenn sich die hohen Erwartungen dann nicht erfüllen. Als Folge werden auch andere, potenzielle KI-Cases nicht mehr ausprobiert. Dabei sollte im Gegensatz zu gängigen Softwarelösungen jedes KI-Projekt mit der Grundeinstellung „Chancen erkennen, aber keine Wunder erwarten“ angegangen werden. KI-Lösungen basieren nun mal auf Zusammenhängen, Mustern und Regeln in den Daten, die sich kaum beeinflussen lassen. Denn was nicht existiert, kann ein Algorithmus auch nicht erlernen.
Das bedeutet: Lassen Sie sich nicht demotivieren, nur weil sich eine Idee nicht umsetzen lässt. Versuchen Sie die Gründe des Scheiterns zu identifizieren oder gehen Sie den nächsten erfolgsversprechenden Use Case an.
2. Fehler: Anwendungsfälle werden unnötig lang weiterverfolgt
Nicht nur Fachbereiche neigen dazu, sich von den Erwartungen an einen bestimmten KI-Ansatz über die Maße mitreißen zu lassen. Mitunter ist es auch der Data Scientist, der von einem nur scheinbar erfolgsversprechenden Anwendungsfall nicht ablassen möchte – zum Schaden des gesamten Projektes. Um dies zu vermeiden, bietet sich ein sogenannter Durchstich an. Hierbei kann anhand eines ersten, einfachen Prototyps frühzeitig und sehr konkret bewertet werden, ob eine Idee tatsächlich machbar ist.
Das hat gleich mehrere Vorteile: Sie verschenken keine unnötigen Ressourcen hinsichtlich Zeit, Geld und Motivation. Gleichzeitig bringt ein solcher Prototyp häufig Grundvoraussetzungen zum Vorschein, durch die ein KI-Projekt auf anderen Wegen doch noch zum Erfolg geführt werden kann.
3. Fehler: Die IT-Abteilung ist alleiniger Treiber des Projektes
Keine Frage: Die technischen Kompetenzen für die Entwicklung einer KI liegen meistens nicht in den Fachbereichen. Deshalb wird oftmals fälschlicherweise der IT die vollständige Verantwortung für ein solches Projekt übertragen – mit möglicherweise negativen Auswirkungen auf den praktischen Nutzen der Lösung. Denn letztendlich kennen die Mitarbeiter in den Fachabteilungen die relevanten Probleme der Kunden sowie die wertschöpfenden Prozesse des eigenen Unternehmens am besten. Somit sind auch sie vielmehr als die IT dazu in der Lage, die für die Projektziele erforderlichen Fragestellungen zu konkretisieren. Ganz abgesehen davon, dass es die fachlich geprägten Anwender sind, die schließlich mit der Lösung im Tagesgeschäft arbeiten sollen.
Daher lautet die einfache Formel: Übertragen Sie die Verantwortung für ein KI-Projekt stets dem jeweiligen Fachbereich, und nicht ausschließlich der IT.
4. Fehler: Die Relevanz von Vertrauen wird unterschätzt
„Vertrauen“ ist ein entscheidender – aber häufig unterschätzter – Schlüssel, um eine KI-Lösung im Unternehmen erfolgreich zu etablieren. Dabei geht es weniger darum, dass die Funktionsweise der Algorithmen für den Endanwender nachvollziehbar ist. Vielmehr muss er die von der KI generierten Ratschläge als vollkommen verlässlich erachten. Nur dann wird die Lösung auch optimal genutzt.
Aber wie lassen sich die Nutzer von der Qualität der Ergebnisse überzeugen? Hilfreich sind beispielsweise laufende Vergleiche zwischen den KI-Empfehlungen und den tatsächlich gelieferten Ergebnissen. Zudem ist es sinnvoll, dem Endanwender zu vergegenwärtigen, dass die KI für die Bewertung von Sachverhalten die gleichen Einflussfaktoren – etwa das Wetter oder den Verkehr – einbezieht, wie er selbst im Kontext seines persönlichen Bauchgefühls.
5. Fehler: Die KI darf sich niemals irren
Die Akzeptanz von KI-Lösungen leidet ebenso unter der vermeintlichen Vorstellung, dass ihre Ratschläge stets zu 100% richtig seien. Jedoch vermag eine KI schneller und genauer sein als der Mensch, allerdings kann auch sie in unserer multikausalen Welt niemals zu jeder Zeit jede Situation korrekt einschätzen.
Hier ist wieder die direkte Kommunikation mit dem Anwender gefragt: Es gilt, ihn gezielt dafür zu sensibilisieren, dass die Ergebnisse auf Wahrscheinlichkeiten basieren. Falls solche Begrifflichkeiten zu abstrakt sind, kann auch eine Definition von Fehlerschwellen helfen, die dem Nutzer verständlich vermitteln, wie sicher die gelieferten Erkenntnisse sind.
6. Fehler: Data Scientists werden nicht weitergebildet
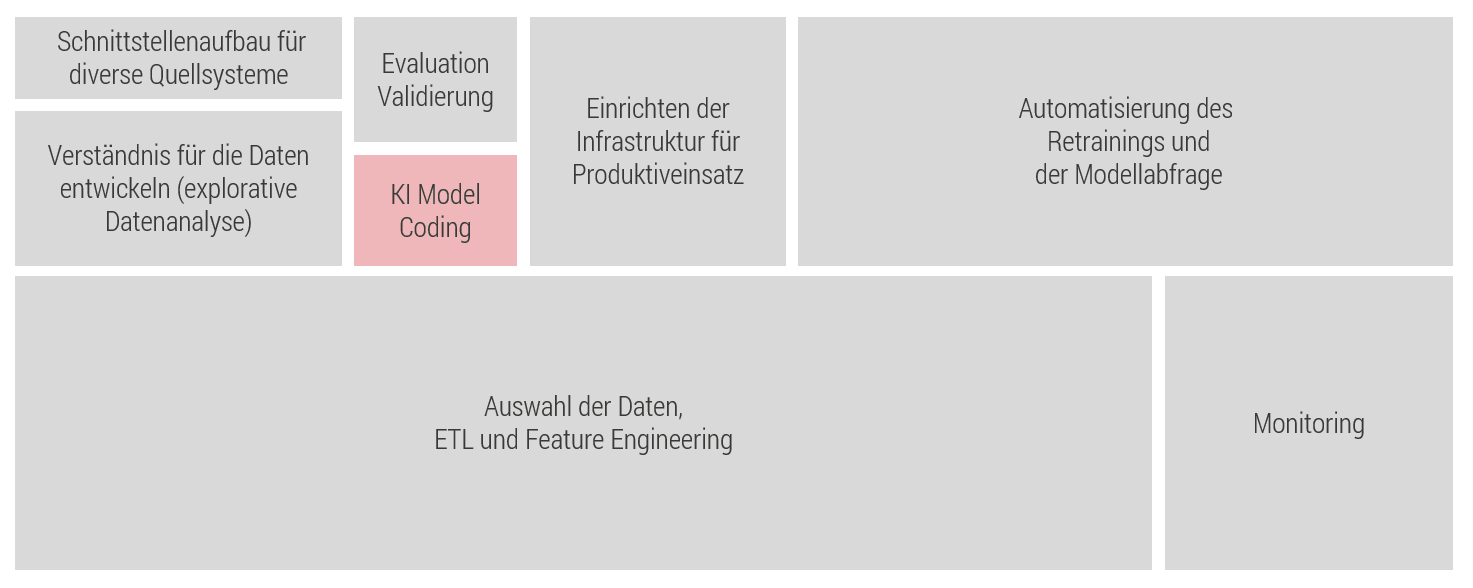
Nicht zuletzt scheitern KI-Lösungen am mangelnden technischen Wissensstand der Mitarbeiter. Nur rein methodische Kentnisse reichen mittlerweile nicht mehr aus. So werden Data Scientists gerne als reine Statistiker beschäftigt, die sich ausschließlich auf die Datenanalyse und das Aufdecken neuer Zusammenhänge konzentrieren sollen. Doch gerade im Kontext einer erfolgreichen KI-Implementierung sind weit mehr Kompetenzen gefragt, auf die die betreffenden Mitarbeiter hin zu schulen sind. Das reicht vom Abgreifen der Daten aus unterschiedlichsten Quellen über den Aufbau komplexer Prozesse für die Datenaufbereitung bis hin zur Bereitstellung einer modellierten KI oder der Automatisierung des Retrainings.
Das heißt: Ein guter Data Scientist muss auch immer ein guter Data Engineer sein. Umgekehrt kann natürlich ein Data Engineer mit methodischen Grundkenntnissen bei der Vertiefung von Machine-Learning-Methoden gefördert werden.
Fazit
Die dargestellte Übersicht an typischen Fehlern bei der Entwicklung von KI-Lösungen macht vor allem eines deutlich: Ein Scheitern ist nicht zwangsläufig auf technische Gründe zurückzuführen. Vielmehr gibt es eine ganze Anzahl weicher Faktoren, die beachtet werden müssen. Dabei gilt es vor allem, das Zusammenspiel zwischen dem projektverantwortlichen Fachbereich, realistischen Zielsetzungen, interdisziplinär aufgestellten Data Scientists sowie einer für Endanwender nachvollziehbaren KI aufeinander abzustimmen.
Wollen Sie mehr zur erfolgreichen Umsetzung von KI-Projekten in Ihrem Unternehmen erfahren? Dann informieren Sie sich weiter auf der Seite Künstliche Intelligenz oder besuchen Sie unser Training Künstliche Intelligenz: Einstieg in die Planung von KI-Projekten.




Kommentare (0)