20.03.2025 Christoph Epping
Real-time data is considered to be one of the most valuable treasure troves for companies. Thanks to modern cloud-based technologies, it is now finally possible to fully harness and integrate this asset in business analyses. The question is: what are the best services available for this setting?
Within our project environment driven by Microsoft Azure, we always sway between Stream Analytics and Databricks Streaming. For our client igus from an industrial context, Databricks has clearly won the race – not necessarily because the service offers general advantages in terms of performance or costs. It simply offers a more homogeneous integration into the existing Databricks landscape. This means that the effort required for data integration and processing is significantly lower.
What did the implementation process look like? What kind of insights and best practices were taken away from the project? Let’s take a closer look at the project and its specific use case.
Databricks Lakehouse calls for Databricks Streaming
igus describes a characteristic scenario from Industry 4.0: The aim is to continuously link data on production and the status of machines with other business data and provide near-real-time visualization as reports and dashboards. In the future, up to 800 systems are to be connected to the solution.
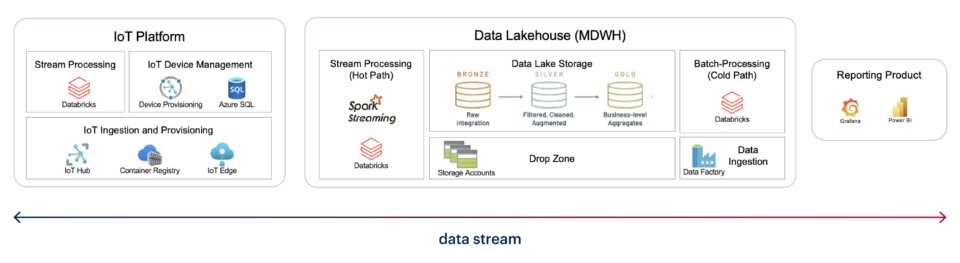
For the initial set up, we used Stream Analytics and were able to meet all requirements. However, in the further course of the project, it became clear that using Databricks Streaming would be more sensible. The main reason being that the existing Data Lakehouse already provides a large amount of the required master data in a processed format. This is why not as much sources are required. Switching to the Databricks service therefore quickly led to tangible savings in terms of time and costs.
What’s more, neither the data sources nor the existing reports and dashboards need adapting when it comes to switching systems. Whatever the task, the right interfaces and software solutions will be available. The only requirement is an individual logic. It’s as simple as that? Generally speaking, yes. However, requirements for modern real-time data streams are quite demanding. As a result, there are a few things to bear in mind, which I will address in the following.
Strict requirements: finding the right solutions
The specifications for the real-time data stream from igus represent the state of the art in terms of Industry 4.0:
- The aim is to enrich streaming data with business information during the processing
- Complex data streams are to be split and parallelized according to different parameters
- Past data from the same stream needs to be accessed in order to determine the production value
- Processing time between submitting and reaching the dashboard cannot exceed three seconds
- If the system is interrupted, it must be ensured that old and new data can be retrieved immediately
- The data should be provided as a Streaming Dataset via Power BI
Our solution meets all of these requirements. For the implementation of Databricks Streaming, we used applyInPandasWithState. In order to be able to allocate the continuous stream of production values to individual shifts, we determine the accumulated sum of the delta values of the current shift rhythm. For each shift, the display on the dashboard is updated live on a daily basis. An in-memory database can be used to save the delta value as well as the last known value. Consequently, the storage account remains available and the processing time is reduced.
applyInPandasWithState offers a dedicated feature – this is the code:
stream = stream.groupBy('MachineId').applyInPandasWithState(
# individually developed feature for state processing
statefunc,
# schema of the data output
"AssembledDelta INTEGER, MachineId STRING, State INTEGER, ShiftDate STRING, InventoryNo STRING",
# schema of the in-memory state chart
"timestamp TIMESTAMP, Assembled INTEGER, State INTEGER",
"append",
GroupStateTimeout.NoTimeout
)
def statefunc(key, pdf_iter, state):
pdf = pd.concat(list(pdf_iter), axis=0)
state_str = ""
# If state exists, combine in-memory state and new arriving stream data
if state.exists:
(old_ts, old_assembled, old_state, ) = state.get
state_str = f"old_ts={old_ts}, old_assembled={old_assembled}, old_state={old_state}"
pdf = pd.concat([pd.DataFrame({'timestamp': [old_ts], 'Assembled': [old_assembled], 'State': [old_state]}), pdf])
# Sort by timestamp to properly forward fill null values and to calculate the delta
pdf = pdf.sort_values(by=["timestamp"])
# ----------- Fill empty rows
pdf["Assembled"] = pdf["Assembled"].replace(to_replace=-1, method="ffill")
pdf["State"] = pdf["State"].replace(to_replace=-1, method="ffill")
# -----------
# Calculate delta value
pdf['AssembledDelta'] = pdf.Assembled.diff()
# Drop the first row from the timestamp sorted state to only keep the latest one
if state.exists: pdf = pdf.iloc[1:]
# Update the in-memory state
state.update((pdf.iloc[-1].timestamp, pdf.iloc[-1].Assembled, pdf.iloc[-1].State,))
# ----------- Shift Date Handling
# Additional logic for output dataframe
# Calculate shift date by extracting the date from the timestamp substracted by 6 hours
pdf['timestamp'] = pdf.timestamp - timedelta(hours=6)
pdf['timestamp'] = pdf['timestamp'].dt.strftime("%Y-%m-%dT%H:%M:%S.%fZ")
pdf = pdf.rename(columns={"timestamp": "ShiftDate"})
pdf.drop(columns=["Assembled"], inplace=True)
# -----------
yield pdf
Databricks Streaming – a brief summary
The Databricks Lakehouse and the surrounding services create a very coherent and complete solution. This is why my number one recommendation would be: If you’re already using Databricks, you don’t even need to explore alternatives. With this in mind, Databricks Streaming offers a high degree of flexibility when it comes to the use of data streams. In particular, applyInPandasWithState is a powerful tool that can be used to process streams across different features. It is also possible to access historical data without having to persist additional data.
What needs to be taken into account is performance, the resulting processing time as well as memory management of the respective cluster; these clusters, however, can be scaled to meet all requirements. Ultimately, it is possible to merge all available data – a well-rounded solution for companies that want to use available real-time data consistently and across departments.
Are you also looking to use real-time data for your business analysis? Then visit our Databricks Lakehouse page.
Zum Autor

Christoph Epping
Senior Consultant – IoT
Christoph Epping gehört zu den Top-IoT-Experten bei ORAYLIS. Gemeinsam mit unseren Kunden realisiert er Echtzeit-Lösungen von der Ideenfindung bis zur konkreten Umsetzung.



Kommentare (0)